

Миграция с «железа» в облако в большинстве случаев уже не кажется чем-то сложным или удивительным — тенденция на развертывание решений в облаке общая и устоявшаяся. Но если с переносом в облачную среду небольших ИТ-компонентов все просто, то в случае с глобальными системами на сотни петабайт данных все несколько иначе — такие кейсы встречаются редко.
Меня зовут Михаил Марюфич. Я руководитель Data Platform в ОК, отвечаю за инфраструктуру для Big Data и машинного обучения. В этой статье я расскажу о нашем опыте переноса Hadoop с Bare Metal в облако: с чего стартовали, какие варианты рассматривали, как выстроили миграцию и с чем сталкивались в процессе.
Исходная инсталляция
Hadoop — один из основных компонентов ИТ-инфраструктуры ОК, который мы активно задействуем для работы с данными от разных источников.
Наш Hadoop — довольно крупная система:
размер кластера в дисках превышает 250 петабайт;
объем оперативной памяти — 200 терабайт, которые распределены по 7 дата-центрам;
выполняет более 10 тысяч задач ежедневно;
имеет федерацию из трех основных кластеров.
В Hadoop две ключевые подсистемы:
YARN;
HDFS.
YARN — подсистема выполнения расчётов. Она интенсивно использует CPU и RAM на машине, на которой развернута. Состоит из:
ресурсного менеджера (resourcemanager), который выделяет ресурсы;
nodemanager, на которых запускаются приложения, потребляющие ресурсы.

HDFS — подсистема хранения данных. Состоит из:
namenode, где хранится информация о блоках;
datanode, где хранятся блоки данных.

В «железе» это выглядит следующим образом:
есть мастер-хосты, где развернуты namenode и resourcemanager;
есть worker-host, где развернуты nodemanager и datanode.

Такая реализация нужна, чтобы эффективно потреблять ресурсы всей машины: например, datanode, как правило, больше задействуют диски, а nodemanager — наоборот.
Чтобы обеспечить работу Hadoop без даунтаймов, мы используем классическую схему c синхронизацией namenode через кворумные журналы (quorum journal):
есть активная namenode, которая пишет информацию;
есть standby namenodes, которые зачитывают логи изменений из журналов, синхронизируют изменения и могут стать активными в любой момент.

К тому же наш Hadoop использует преимущества зон доступности — фактически у каждого блока реплики находятся в трех удаленных друг от друга дата-центрах. Это позволяет гарантировать отказоустойчивость решения даже в случае временного или полного выхода одного ЦОДа из строя.

Проблемы исходной реализации и пути их решения
У нашего Hadoop на железе было несколько «слабых мест», которые хотелось устранить или улучшить.
Эксплуатация. Большинство задач, связанных с администрированием решения и обслуживанием инфраструктуры нам приходилось частично или полностью выполнять вручную. Замена/добавление узлов, обновление конфигураций на кластере, развертывание новых кластеров — многие моменты требовали вовлечения специалистов.
Мутабельные состояния компонентов. У нас хорошо развиты практики работы с физическим оборудованием, что позволяет минимизировать появление мутабельных состояний. Вместе с тем, полностью исключить ситуации, когда на части узлов оказываются неконсистентные с другими узлами кластера конфигурации или версии ПО, на практике не получилось, что чревато инцидентами.
Объединение Compute и Storage. Мы хотели разделить Compute и Storage, чтобы повысить эффективность потребления ресурсов. Потребление мощностей неравномерно в течение дня, на ночное время приходится пик вычислительных нагрузок — по нашему внутреннему SLA все расчёты должны быть закончены к утру. В итоге нам нужно выделять мощности на проект с большим запасом, который будет простаивать большую часть времени. В схеме с разделенным compute и storage мы получаем возможность расширить кластер в моменты высоких нагрузок, а когда ресурсы не востребованы — передавать их другим приложениям.

График потребления CPU.
То есть нам нужна была реализация, которая позволила бы:
обеспечить независимое горизонтальное и вертикальное масштабирование compute- и storage-слоёв;
повысить удобство эксплуатации (ввод-вывод узлов, создание новых кластеров и других операций);
поддерживать иммутабельное состояние компонентов.
Добиться этого можно было тремя способами.
Переход на Managed-инфраструктуру. Подход подразумевает использование инфраструктуры и сервисов стороннего вендора, который берет на себя задачи администрирования и обслуживания. Вариант позволяет по умолчанию получить разделение compute и storage, а также уйти от эксплуатационных трудностей. Но нам он не подходил — мы не можем хранить данные пользователей в публичных облаках, да и стоимость развертывания и поддержки такого решения под наш объем данных в стороннем облаке неоправданно велика.
Смена стека технологий. Потенциально мы могли применить в качестве storage что-то compatible (ceph, apache ozone, свое решение), а в качестве compute — spark over k8s или trino over k8s. Это наиболее популярные варианты решений. Но в нашем случае такой подход не оправдан: во-первых, у нас уже есть hdfs, который нас целиком устраивает, во-вторых, у нас есть не только Spark, но и другие legacy-инструменты, а Kubernetes нет вовсе. К тому же менять весь стек ради получения нескольких преимуществ — не самый очевидный путь.
Развертывание решения на внутренней инфраструктуре. В VK есть собственный контейнерный оркестратор One-Cloud. Ближайший его аналог из open-source — Kubernetes. По сути, One-Cloud — внутреннее облако, которым пользуются многие бизнес-юниты холдинга (OK, ВКонтакте, Дзен и другие). То есть мы можем развернуть Hadoop в One-Cloud и разделить compute/storage (hdfs/yarn). Причём такой путь уже проторен — подобные проекты уже реализовывали Uber и Yandex. Для нас этот вариант стал приоритетным — он эволюционный и согласуется со стратегией развития компании.
От идеи к первым проработкам
One-Cloud — это большой контейнерный оркестратор, который управляет распределением всех ресурсов. Фактически он решает, где будет размещен тот или иной инстанс приложения. Например, nodemanager и datanode могут быть автоматически размещены на разных хостах.

Главное условие для системы — максимально использовать доступные ресурсы. Для нас основное преимущество облака — решение проблемы менеджмента ресурсов и возможность гибко масштабировать компоненты без необходимости их ручного переноса между хостами.
Чтобы развернуть кластер в облаке, достаточно небольших манифестов с указанием Docker-образа, количества ресурсов и некоторых дополнительных параметров.
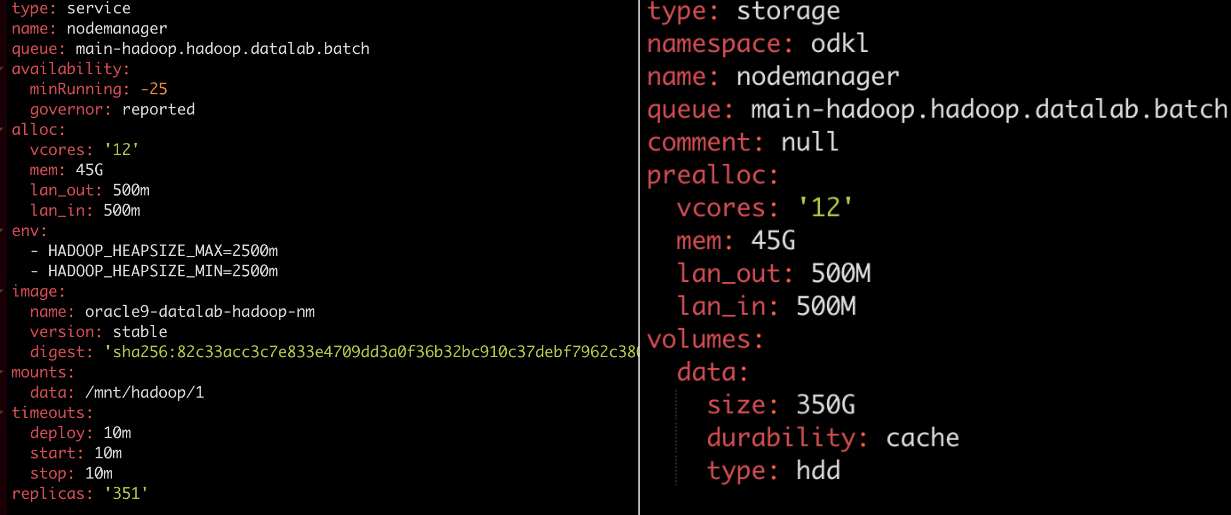
На первый взгляд, ничего сложного. Но для работы Hadoop нам нужно было предварительно решить несколько проблем.
Конфигурация. Во внешнем мире конфигурирование решают разными способами. В ОК для этого применяется собственная система — Portal Management System (PMS). Инструмент проинтегрирован со всем продакшеном. Он позволяет писать конфигурации к отдельному приложению и подписываться на изменения этих конфигураций. Используя PMS, можно доставлять файлы с конфигурациями в контейнеры Hadoop. В итоге задачи менеджмента конфигураций мы закрываем с помощью Portal Management System.
Kerberos. В Hadoop есть Kerberos — сетевой протокол аутентификации с использованием центра доверия. Он применяется для аутентификации клиентов кластера и узлов внутри кластера. Фактически это единственный способ настроить security в Hadoop. В реализации на Bare Metal мы контролировали эти процессы в полуручном режиме, но для облака сразу искали способ полной автоматизации. Для этого мы написали Kerberos Registration manager — компонент, который сканирует топологию новых кластеров, находит узлы без учётки и создаёт их в Kerberos, а также создаёт keytabs и заливает их в Vault.

В итого пайплайн создания компонентов кластера выглядит так:
Выполняем сабмит манифеста в облако.
Облако определяет сервер, подходящий для запуска. Стартует контейнер.
В контейнер доставляются конфигурации, сертификат, kerberos keytab.
Стартует Hadoop. Узел Hadoop входит в кластер.
Так мы можем создать кластер, в котором будут разделены Compute и Storage, HDFS и YARN.

От теории к реальным петабайтам
После выработки алгоритма создания кластера в облаке, стал вопрос переноса сотен петабайтов данных с физического оборудования в облачную среду.
Есть два основных подхода к миграции:
постепенный перевод приложений на новый кластер;
постепенное добавление облачных узлов.
Постепенный перевод приложений на новый кластер
Метод подразумевает развертывание облачного кластера и последовательную миграцию в него целых приложений или их крупных компонентов. Также можно реализовать несколько усложненную, но более экономичную схему, при которой облачный кластер постепенно расширяется, соразмерно «схлопыванию» физической инфраструктуры:
постепенно переводим запись;
копируем историю;
наращиваем кластер, освобождаем старые ресурсы.

Способ надёжен, но у него есть несколько недостатков:
процесс требует ручного управления и контроля;
копирование данных может затянуться на долгий срок;
на момент миграции надо перестраивать бизнес-логику обращения с данными, а пользователи вынуждены работать одновременно с несколькими кластерами: читать в одних, писать в другие.
В результате этот вариант нам не подошёл.
Постепенное добавление облачных узлов
Метод подразумевает, что параллельно со старым кластером в облаке создаётся новая, пустая datanode, которая сразу включается в кластер.

Кластер начинает писать данные на новую ноду. Параллельно начинается вывод одной из старых нод через процедуру декомиссии (блоки постепенно реплицируются на другие узлы).
После того, как старая нода опустеет, её можно вывести из кластера.

По такому алгоритму можно бесшовно перенести в облако все данные без влияния на конечного пользователя.

Последним этапом в облако переносится namenode.

После этого миграцию Hadoop в облако можно считать завершённой. Причём такой подход исключает даунтайм и потерю данных.
Мы начали миграцию по этому пути, но…
Миграция и первые несоответствия ожиданиям
После запуска процедуры переноса данных на ноду в облаке мы получили скорость репликации на уровне 2 тысяч блоков в минуту. Это примерно 250 Гб. С учётом того, что у нас даже в не самом большом кластере было около 150 млн блоков, на миграцию с такой скоростью нужно было около 52 дней, что непозволительно долго.
Мы начали разбираться, изучили Namenode и увидели, что ядра не загружены, но в фоне крутится RedundancyMonitor, метод — computeDatanodeWork().

Он отвечает за назначение заданий на репликацию нод. При этом алгоритм выбора датанод для репликации примерно следующий:
Выбираются случайные датаноды в случайных дата-центрах.
Проверяется соответствие политике размещения блоков — важно, чтобы были выбраны три датаноды в трех разных ЦОДах.
Если условие не выполняется, цикл повторяется.
Наш анализ показал, что 90% времени уходит на выбор случайных датанод и случайных ЦОДов. Примечательно, что обычно это быстрые операции. Чтобы найти первопричину проблемы, мы начали углубляться в реализацию на уровне кода.
По дефолту порядок выбора случайной ноды такой:
Проверяются все датаноды в ЦОДе.
Проверяется наличие дисков нужного типа.
Если диски есть, нода добавляется в список.
Из списка выбирается случайная датанода.

В такой реализации основная загвоздка была с проверкой на наличие дисков соответствующего типа — вероятно при разработке не учитывали, что в списке может быть не 10 элементов, а, например, 150, что кратно увеличивает времязатраты.
Но в нашей инсталляции только HDD-диски, то есть проверять их соответствие не нужно. Это позволило немного переписать код и существенно упростить схему — теперь выбор всегда рандомный без дополнительных согласований.

Такие манипуляции позволили нам повысить скорость репликаций до 15 тысяч блоков в минуту (2 ТБ против 250 ГБ до внесения изменений). В итоге время на миграцию сократилось с 52 до 7 дней.
После этого оставался вопрос с миграцией мастеров.
Миграция мастеров
Алгоритм миграции мастеров довольно прозрачный.
Например, есть кластер из двух namenode — одна из них активная, а другая standby. Есть три журнала, в которые они пишут с кворумом.

В облако добавляется новая namenode и пара журналов (для сохранения нечетности).

После проверки корректности, namenode в облаке делают активной.

Одна из старых namenode выводится из строя.

По такому же принципу в облако переносится вторая namenode standby. После этого оставшееся «железо» выводится из кластера. Миграция мастеров завершена.

Но есть пара нюансов, с которыми пришлось разбираться.
Невозможность динамического добавления компонентов. В Hadoop нельзя динамически добавлять новые namenode и журналы. Такую функциональность обещают в ближайшее время, но пока её нет. В итоге нам пришлось вручную перезагружать ноды в нескольких кластерах. Это не критично, но некие неудобства доставило.
Сложность бесшовного переноса данных. С namenode работает много клиентов и разрыв связи с любым из них может привести к сбою на уровне процессов — например, к невозможности читать и писать, что равно локальному даунтайму. При этом нам было важно, чтобы на пользователях, работающих с Hadoop, миграция не отразилась.

Трудность в том, что топология кластера хранится на клиенте в файле hdfs-site.xml.

Если при создании новой облачной namenode не добавить информацию о ней на все клиенты и не выполнить соответствующую переконфигурацию клиента, система не сможет работать с кластером, запросы будут вести на standby namenode. Чтобы исключить такие проблемы, конфигурации топологии кластера надо доставить на каждого клиента и обновлять при их изменении.
В нашем случае эту проблему решает, то, что конфигурации в большинстве приложений применяются динамически и хранятся в Portal Management System, который в данном случае выступает единым источником истины. Для Hadoop мы предварительно централизовали все конфиги, поэтому нам было достаточно указать информацию о новой ноде в одном месте и она автоматически подтягивается во всех клиентах кластера.

После этого миграция была завершена. Профит!
Жизнь после миграции
Довольно быстро после начала работы Hadoop в облаке мы столкнулись с двумя обстоятельствами.
Во-первых, общая производительность расчётов упала на 10-15%. Потеря была отчасти ожидаемой и предсказуемой, поскольку мы отказались от локальной работы с данными и вызовов по сети стало больше. Для нас такая динамика не критична — потеря производительности с лихвой окупается преимуществами, полученными от работы в облаке.
Во-вторых, мы начали отмечать общую деградацию производительности расчётов.
Так, мы ежедневно проводим расчёты DWH. «Красненькое» — наша внутренняя прокси-метрика, которая позволяет понять, что когда расчёты завершены успешно.

При работе с Hadoop на Bare Metal для нас было нормой, что расчёты заканчиваются утром — максимум до 11:00. После миграции в облако это условие соблюдалось. Но спустя некоторое время началась резкая деградация — окончание расчётов сместилось сначала на 12:00, потом на 16:00, а после и вовсе на 18:00.

Причём, согласно статистике, расчёты занимают всю доступную память. А часть расчётов даже не успевает считаться день в день.

Дальнейший анализ показал, что проблемы локализуются на IO — с некоторых datanode наши nodemanager считывают в 10-100 раз медленнее, чем с других.

Причина оказалась в IOCost — это технология, которая позволяет изолировать приложения между собой по диску и предоставлять им гарантии чтения/записи. Например, чтобы Kafka могла комфортно «соседствовать» с любым другим приложением, использующим диск.

В нашем случае оказалось, что есть прямая зависимость от включения IOCost на новые ЦОДы. Технологию постепенно раскатывали на новые ЦОДы, чтобы обеспечить лучшие гарантии, но это только усугубляло деградацию.

В моменте мы решили откатить изменения (отказаться от IOCost) и увидели, что негативный эффект полностью нивелирован — расчёты снова начали заканчиваться до обеда и даже раньше (к 6-7 утра). Hadoop’у стало комфортно.

В дальнейшем, чтобы обеспечить гарантии для «приложений-соседей», мы перепрофилировали решение и смогли включить IOCost на весь production без аффекта на Hadoop и другие приложения.

Так мы закрыли последний гештальт и окончательно перешли на Hadoop в облаке.
Наши результаты и выученные уроки
Вся миграция — от идеи до финала — заняла у нас 1,5 года и была проведена силами всего трёх специалистов.
Переход в облако дал нам ряд преимуществ. Мы:
получили возможность гибко масштабировать инфраструктуру и сэкономили на закупках N миллионов за счет возможности покупать только диски;
делегировали задачи администрирования и обслуживания железа команде One- Cloud;
полностью автоматизировали рутинные операции с Hadoop (расширение кластера, замена сломанных дисков/машин и другие);
объединили вычислительные кластеры, научились ночью брать больше ресурсов и ускорили расчёты;
сделали Hadoop as a service, который теперь предоставляем другим бизнес-юнитам холдинга.
На основе нашего опыта можно сформулировать несколько рекомендаций:
Не бойтесь читать и править исходный код системы, если это нужно для задачи.
Покрывайте большим количеством метрик все компоненты Hadoop и вовремя реагируйте на подозрительные сигналы.
Непонимание любого эффекта — потенциальная проблема, которая может стать реальной в самый неудобный момент. С любыми эффектами лучше разбираться сразу.
